The Expectation Maximization Algorithm
The Expectation Maximization (EM) algorithm is a widely used powerful algorithm that can be used to estimate the parameters of a statistical model. It’s similar to the famous Newton-Raphson method, the difference is that the Expectation Maximization (EM) algorithm is used when the data has missing values or when the model has latent variables. It has been applied to a variety of problems, including clustering, density estimation, and parameter estimation for hidden Markov models.
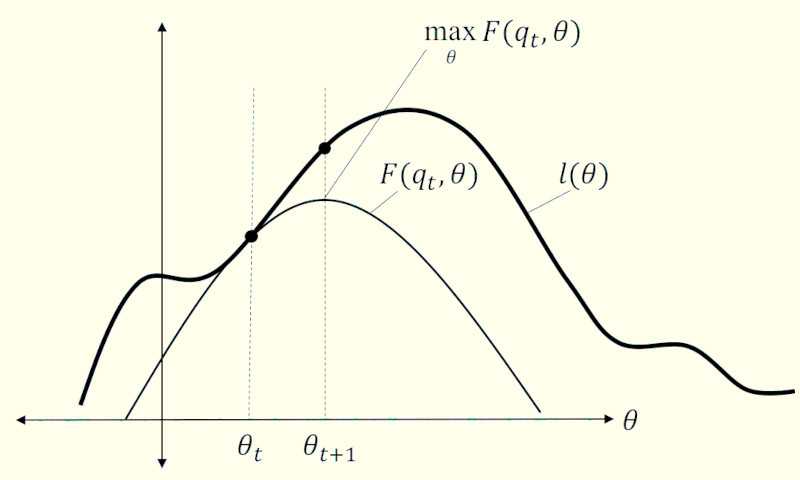
The EM algorithm is an iterative algorithm that consists of two main steps: the E-step and the M-step. In the E-step, the algorithm computes the expected value of the latent variables given the observed data and the current estimate of the parameters. In the M-step, the algorithm maximizes the likelihood function with respect to the parameters, using the expected values of the latent variables computed in the E-step. We repeat these two steps until the algorithm converges to a local maximum of the likelihood function.
Basic Definitions
Convex Set
The Convex Set is defined as a set of points such that the line segment connecting any two points in the set lies entirely within the set. Formally, a set is a convex set if for any two points and in , the line segment connecting and lies entirely within .
Convex Function & Concave Function
- Convex Function
The Convex Function is defined on top of the convex set. A twice-differentiable function of a single variable is convex if and only if its second derivative is nonnegative on its entire domain, and its domain should be a convex set. e.g. is a convex function if for all in the domain of .
- Concave Function
The Concave Function is defined on top of the convex set. A twice-differentiable function of a single variable is concave if and only if its second derivative is nonpositive on its entire domain, and its domain should be a convex set. e.g. is a concave function if for all in the domain of .
Jensen’s Inequality
For a convex function and a random variable , the following inequality holds:
similarly, but oppositely, for a concave function and a random variable , the following inequality holds:
Maximum Likelihood Estimation
In statistics, the Maximum Likelihood Estimation (MLE) is a method used to estimate the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
Assuming we have a set of independent and identically distributed (i.i.d.) random variables , and the distribution function is defined as:
where is the parameter of the distribution, and we could define the likelihood function as:
The Maximum Likelihood Estimation is to find the parameter that maximizes the likelihood function , i.e.
The Expectation Maximization Algorithm
Definitions
As mentioned before, the Expectation Maximization (EM) algorithm is a loop to iterate between the E-step and the M-step until the algorithm converges to a local maximum of the likelihood function. Let’s say, we have a set of observed data on a random variable , and a latent variable , and the joint distribution of and is defined as:
where is the probability mass/density function, and are values for and , and parameterizes the distribution.
In practice, we often don’t observe the latent variable , and we wish to find the value for that makes most likely under our model. Since we have not observed , we take a logarithm of the likelihood function, and the function must marginalize over :
or,
The E-step
The E-step is to compute the expected value of the latent variables given the observed data and the current estimate of the parameters. The expected value of the latent variables is computed using the current estimate of the parameters and the observed data. The E-step is called the “expectation” step because it computes the expected value of the latent variables given the observed data and the current estimate of the parameters.
The M-step
The M-step is to maximize the likelihood function with respect to the parameters, using the expected values of the latent variables computed in the E-step. The M-step is called the “maximization” step because it maximizes the likelihood function with respect to the parameters.
Conclusion
The Expectation Maximization (EM) algorithm is a powerful algorithm that can be used to estimate the parameters of a statistical model. It is a versatile algorithm that can be used in many different settings, and it is an important tool to have in your machine learning toolbox.