My Understanding of Word2Vec
The appearance of word2vec has greatly promoted the development of natural language processing. It is a classic model for generating word embeddings. In this article, I will explain my understanding of word2vec.
Objective
The objective of word2vec is to learn word embeddings from a large corpus of text. Word embeddings are dense vectors of real numbers, one for each word in the vocabulary. In the context of neural networks, they are used to represent words in such a way that words that have similar meanings will have similar representation. There are two main methods to train word embeddings: CBOW (Continuous Bag-of-Words Model) and Skip Gram (Continuous Skip-gram Model).
- CBOW: Predict the current word based on the context
- Skip Gram: Predict the context based on the current word
In both training methods, the input is a one-hot vector representing the current word, and the output is a probability distribution over the vocabulary. The last hidden layer in the middle layer is the word embedding.
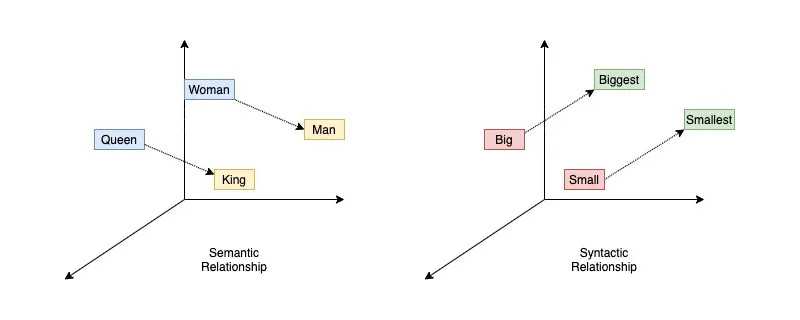
The most attractive feature of word2vec is that it can capture both the semantic and syntactic information of words. The semantic information refers to the meaning of words, such as the relationship between king and queue. The syntactic information refers to the relationship between words, such as the relationship between small and smallest.
The process of training word embeddings is similar to the process of baby language learning. The meaning of each word is inferred from the context. Although it does not solve the actual meaning of each word, it is theoretically applicable to various languages - analytic language (such as Chinese) / synthetic language (fusional language, such as English; agglutinative language, such as Japanese).
Important Functions
Annotations
- : loss function
- : probability
- : training corpus
- : vocabulary
- : context window size
- : word
- : word vector
Loss Function of CBOW
Loss Function of Skip Gram