My Understanding of Transformers and Self-Attention
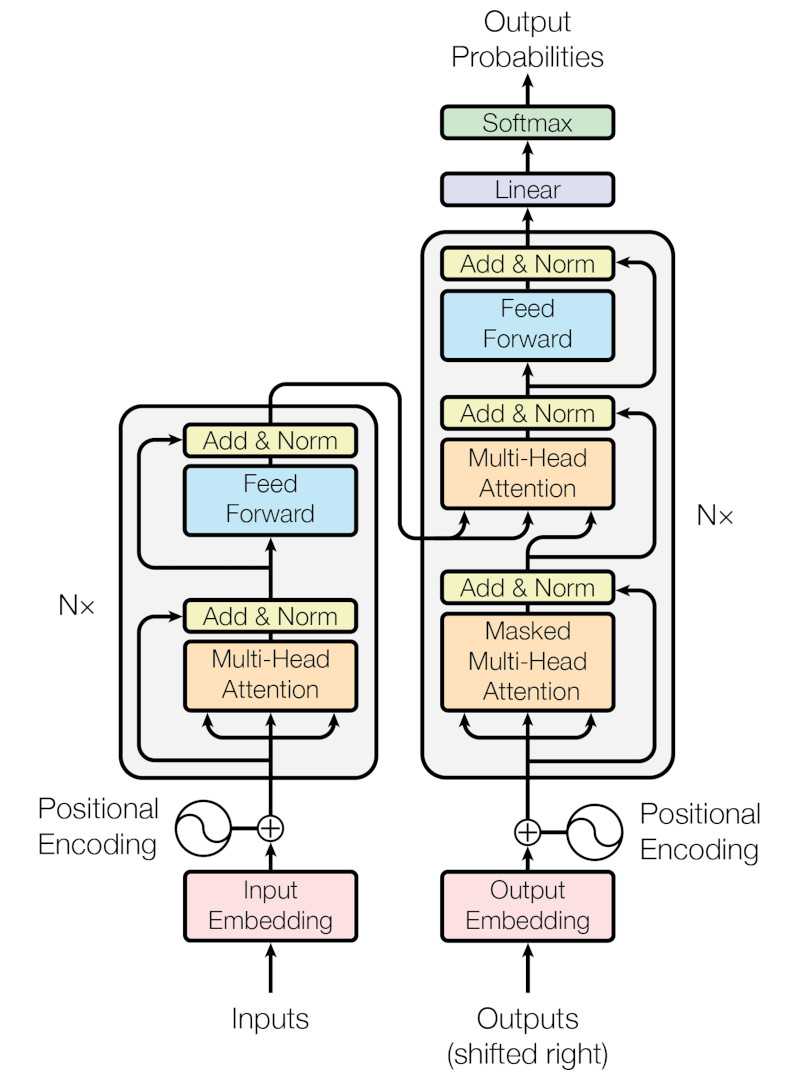
The Transformer is a great breakthrough in the field of deep learning, especially in natural language processing (NLP). It was introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017. The Transformer architecture has revolutionized the way we approach sequence-to-sequence tasks, such as machine translation, text summarization, and question answering.
Background
Before the Transformer, the dominant architectures for sequence-to-sequence tasks were Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). RNNs, such as LSTM and GRU, are designed to handle sequential data by maintaining a hidden state that captures information from previous time steps. However, RNNs suffer from the vanishing gradient problem, making it difficult to learn long-range dependencies in sequences. CNNs, on the other hand, can capture local patterns in sequences but struggle with modeling long-range dependencies.
The Transformer architecture addresses these limitations by introducing the self-attention mechanism, which allows the model to weigh the importance of different parts of the input sequence when making predictions. This enables the model to capture long-range dependencies more effectively.
Transformer Architecture
The Transformer architecture consists of an encoder and a decoder, each composed of multiple layers. The encoder processes the input sequence, while the decoder generates the output sequence.
Q, K, V Matrices
In the self-attention mechanism, each token in the input sequence is represented by three vectors: Query (Q), Key (K), and Value (V). These vectors are obtained by multiplying the token’s embedding with learned weight matrices. The Q, K, and V matrices are essential for computing attention scores and generating the output.
- Q: Represents the token for which we are calculating attention.
- K: Represents the tokens that we are attending to.
- V: Represents the actual information of the tokens that we want to aggregate based on the attention scores.
Encoder
The encoder consists of a stack of identical layers, each containing two main components: multi-head self-attention and position-wise feed-forward networks.
- Multi-Head Self-Attention: This mechanism enables the model to simultaneously attend to different parts of the input sequence. It computes attention scores for each token in the sequence with respect to all other tokens, enabling the model to capture relationships between tokens regardless of their distance in the sequence.
- Position-Wise Feed-Forward Networks: After the self-attention layer, each token’s representation is passed through a feed-forward neural network, which consists of two linear transformations with a ReLU activation in between. This helps to introduce non-linearity and further process the information.
Decoder
The decoder is also composed of multiple layers, similar to the encoder, but with an additional component called masked multi-head self-attention. This component ensures that the model only attends to previous tokens in the output sequence during training, preventing it from “cheating” by looking ahead.
- Masked Multi-Head Self-Attention: This mechanism is similar to the multi-head self-attention in the encoder but includes a masking step to prevent the model from attending to future tokens in the output sequence.
- Encoder-Decoder Attention: This layer allows the decoder to attend to the encoder’s output, enabling it to incorporate information from the input sequence when generating the output.
- Position-Wise Feed-Forward Networks: Similar to the encoder, each token’s representation in the decoder is passed through a feed-forward neural network.
Self-Attention Mechanism
The self-attention mechanism is the core component of the Transformer architecture. It allows the model to weigh the importance of different tokens in the input sequence when making predictions. The self-attention mechanism can be broken down into three main steps: computing query, key, and value vectors; calculating attention scores; and generating the output.
- Query, Key, and Value Vectors: For each token in the input sequence, three vectors are computed: the query vector (Q), the key vector (K), and the value vector (V). These vectors are obtained by multiplying the token’s embedding by learned weight matrices.
- Calculating Attention Scores: The attention scores are computed by taking the dot product between the query vector of a token and the key vectors of all other tokens in the sequence. The scores are then scaled and passed through a softmax function to obtain attention weights, which represent the importance of each token in the sequence with respect to the current token.
- Generating the Output: The output for each token is obtained by taking a weighted sum of the value vectors, using the attention weights computed in the previous step. This allows the model to incorporate information from other tokens in the sequence when generating the output for the current token.
Conclusion
The Transformer architecture and self-attention mechanism have significantly advanced the field of deep learning, particularly in natural language processing. By addressing the limitations of previous architectures like RNNs and CNNs, the Transformer has enabled the development of powerful models such as BERT, GPT, and T5, which have achieved state-of-the-art performance on various NLP tasks. The ability to capture long-range dependencies and model complex relationships in sequences has made the Transformer a foundational architecture in modern deep learning.