My Understanding of Consistent Hashing
In computer science, consistent hashing is a special kind of hashing technique such that when a hash table is resized, only keys need to be remapped on average, where is the number of keys and is the number of slots. This is in contrast to traditional hash tables, where a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.
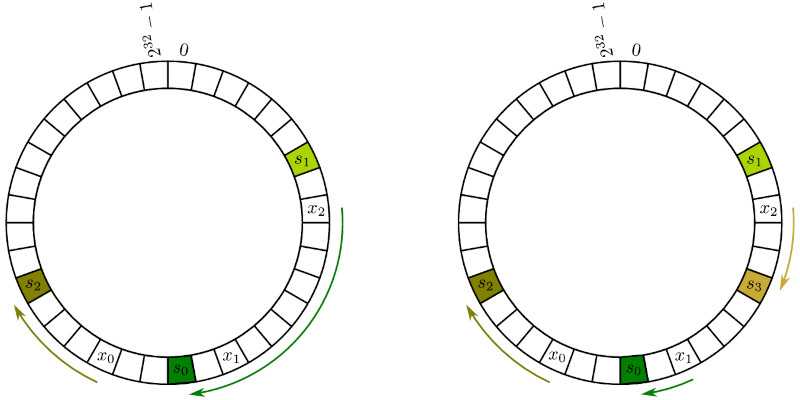
We use consistent hashing to distribute data across a cluster of nodes. The main idea is to use a hash function to map both the keys and the nodes to a fixed-size space (usually a circle). When a new node is added or removed, only a few keys need to be remapped, which minimizes the disruption to the system.
Main Supported Operations
- Insert into the cluster: To insert a new data item, we first compute its hash value and find the node responsible for that hash value. This is done by finding the successor of the hash value in the hash ring.
- Delete from the cluster: To delete a data item, we find the node responsible for that item using its hash value and remove it from that node.
- Get from the cluster: To retrieve a data item, we compute its hash value and find the node responsible for that hash value. We then retrieve the data item from that node.
- Insert a server into the cluster: When a new server is added, we compute its hash value and find the keys that need to be moved to the new server. This is done by finding the successor of the hash value in the hash ring.
- Delete a server from the cluster: When a server is removed, we find the successor of its hash value and move the keys from the removed server to the successor server.
- Get all data from a server: To retrieve all data items from a specific server, we can iterate through the data items stored on that server and return them.
- Get all servers in the cluster: To retrieve all servers, we can iterate through the nodes in the cluster and return their identifiers.